


Wikimedia at the University of Edinburgh

Reasons to engage in the conversation
With about 17 billion page views every month, it’s safe to say that most of us have heard of Wikipedia and maybe even use it on a regular basis. However, most people don’t realise that Wikipedia is the tip of the iceberg. Its sister sites include a media library (Wikimedia Commons), a database (Wikidata), a library of public domain texts (Wikisource), and even a dictionary (Wiktionary) – along with many others, these form the Wikimedia websites.
While the content is all crowd-sourced, the Wikimedia Foundation in the US maintains the hardware and software the websites run on. Wikimedia UK is one of dozens of sister organisations around the globe who support the mission of the Wikimedia websites to share the world’s knowledge.
Today, Wikipedia is the number one information site in the world, visited by 500 million visitors a month; the place that students and staff consult for pre-research on a topic. And considered, according to a 2014 Yougov survey, to be trusted more than the Guardian, BBC, Telegraph and Times. Perhaps because its commitment to transparency is an implicit promise of trust to its users where everything on it can be checked, challenged and corrected.

The University of Edinburgh and Wikimedia UK – shared missions.
Wikimedia at an ancient university
The Edinburgh residency
In January 2016, the University of Edinburgh and Wikimedia UK partnered to host a Wikimedian in Residence for twelve months. This residency marks something of a paradigm shift as the first in the UK in supporting the whole university as part of its commitment to skills development and open knowledge.
Background to the residency
The University of Edinburgh held its first editathon – a workshop where people learn how to edit Wikipedia and start writing – during the university’s midterm Innovative Learning Week in February 2015. Ally Crockford (Wikimedian in Residence at the National Library of Scotland) and Sara Thomas (Wikimedian in Residence at Museums & Galleries Scotland) came to help deliver the ‘Women, Science and Scottish History’ editathon series which celebrated the Edinburgh Seven; the first group of matriculated undergraduate female students at any British university.

Timeline of the Wikimedia residencies in Scotland to date. The University of Edinburgh residency was the first residency in the UK to have a university-wide remit. Martin Poulter was Wikimedian in Residence at the Bodleian Library before beginning a 2nd residency at the University of Oxford on a university-wide remit.

Melissa Highton, Assistant Principal for Online Learning at the University of Edinburgh.
“The striking thing for me was how quickly colleagues within the University took to the idea and began supporting each other in developing their skills and sharing knowledge amongst a multi-professional group. This inspired me to commission some academic research to look at the connections and networking amongst the participants and to explore whether editathons were a good investment in developing workplace digital skills.”– Melissa Highton – Assistant Principal for Online Learning.
This research, conducted by Professor Allison Littlejohn, found that there was clear evidence of informal & formal learning going on. Further, that “all respondents reported that the editathon had a positive influence on their professional role. They were keen to integrate what they learned into their work in some capacity and believed participation had increased their professional capabilities.”
Since successfully making case for hosting a Wikimedian in Residence, the residency’s remit has been to advocate for knowledge exchange and deliver training events & workshops across the university which further both the quantity & quality of open knowledge and the university’s commitment to embedding information literacy & digital literacy in the curriculum.
Wikimedia UK and the University of Edinburgh – shared missions
Edinburgh was the first university to be founded with a ‘civic’ mission; created not by the church but by the citizens of Edinburgh for the citizens of Edinburgh in 1583. The mission of the university of Edinburgh is “the creation, curation & dissemination of knowledge”. Founded a good deal later, Wikipedia began on January 15th 2001; the free encyclopaedia is now the largest & most popular reference work on the internet.
Wikimedia’s vision is “imagine a world in which every single human being can freely share in the sum of all knowledge”. It is 100% funded by donations and is the only non-profit website in the top ten most popular sites.

Wikipedia – the world’s favourite site for information.
Addressing the knowledge gap
While Wikipedia is the free encyclopaedia that anyone can edit, not everyone does. Of the 80,000 or so monthly contributors to Wikipedia, only around 3000 are termed very active Wikipedians; meaning the world’s knowledge is often left to be curated by a population the size of a village (roughly the size of Kinghorn in Fife… or half of North Berwick). While 5.4 million articles in English Wikipedia is the largest of the 295 active language Wikipedias, it is estimated that there would need to be at least 104 million articles on English Wikipedia alone to cover all the notable subjects in the world. That means as of last month, English Wikipedia is missing approximately 99 million articles.
Less than 15% of women edit Wikipedia and this skews the content in much the same way with only 17.1% of biographies about notable women. The University of Edinburgh has a commitment to equality and diversity and our Wikimedia residency therefore has a particular emphasis on open practice and engaging colleagues in discussing why some areas of open practice do have a clear gender imbalance. In this way many of our Wikipedia events focused on addressing the gender gap as part of the university’s commitment to Athena Swan; creating new role models for young and old alike. Role models like Janet Anne Galloway, advocate for higher education for women in Scotland, Helen Archdale (journalist and suffragette), Mary Susan McIntosh (sociologist and LGBT campaigner) among many many more.

Pages created at Women in Red meetings at the University of Edinburgh editing sessions.
That’s why it is enormously pleasing that over the whole year, 65% of attendees at our events were female.
Sharing knowledge
The residency has, at its heart, been about making connections. Both across the university’s three teaching colleges and beyond; with the city of Edinburgh itself. Demonstrating how staff, students and members of the public can most benefit from and contribute to the development of the huge open knowledge resource that are the Wikimedia projects. And we made some significant connections over the last year in all of these areas.
Inviting staff & students from all different backgrounds and disciplines to contribute their time and expertise to the creation & improvement of Wikipedia articles in a number of events has worked well and engendered opportunities for collaborations and knowledge exchange across the university, with other institutions across the UK; and across Europe in the case of colleagues from the MRC Centre for Regenerative Medicine working with research partner labs.

Wikipedia in the Classroom – 3 assignments in Year One. Doubled in Year Two.
Ultimately, what you wanted attendees to get from the experience was this; the idea that knowledge is most useful when it is used; engaged with; built upon. Contributing to Wikipedia can also help demonstrate research impact as there is a lot of work going on to ensure that Wikipedia citations to scholarly works use the DOI. The reason being that Wikipedia is already the fifth largest referrer of traffic through the DOI resolver and this is thought to be an underestimate of its true position.
Not just Wikipedia

Knowledge doesn’t belong in silos. The interlinking of the Wikimedia projects for Robert Louis Stevenson.
Introducing staff and students to the work of the Wikimedia Foundation and the other 11 projects has been a key part of the residency with a Wikidata & Wikisource Showcase held during Repository Fringe in August 2016 which has resulted in some out-of-copyright PhD theses being uploaded to Wikisource, and linked to from Wikipedia, just one click away.
Wikisource is a free digital library which hosts out-of-copyright texts including: novels, short stories, plays, poems, songs, letters, travel writing, non-fiction texts, speeches, news articles, constitutional documents, court rulings, obituaries, and much more besides. The result is an online text library which is free to anyone to read with the added benefits that the text is quality assured, searchable and downloadable.

Sharing content to Wikisource, the free digital library, and linking to Wikipedia one click away.
Wikidata is our most exciting project with many predicting it will overtake Wikipedia in years to come as the dominant project. A free linked database of machine-readable knowledge, Wikidata acts as central storage for the structured data of all 295 different language Wikipedias and all the other Wikimedia sister projects.

Timeline of Female alumni of the University of Edinburgh generated from structured linked open data stored in Wikidata.
“How can you trust Wikipedia when anyone can edit it?”
This is the main charge levelled against involvement with Wikipedia and the residency has been making the case for re-evaluating Wikipedia and for engendering a greater critical information literacy in staff & students. And that’s the thing. Wikipedia doesn’t want you to cite it. It is a tertiary source; an aggregator of articles built on citations from reliable published secondary sources. In this way it is reframing itself as the ‘front matter to all research.’

Wikipedia has clear policy guidelines to help ensure its integrity.
Verifiability – every single statement on Wikipedia needs to be backed up with a citation from a reliable published secondary source. So an implicit promise is made to our users that you can go on there and check, challenge and correct the verifiability of any statement made on Wikipedia.
No original research – while knowledge is created everyday, until it is published by a reliable secondary source, it should not be on Wikipedia. The presence of editorial oversight is a key consideration in source evaluation therefore, however well-researched, someone’s personal interpretation is not to be included.
Neutral point of view – many subjects on Wikipedia are controversial so can we find common truth in fact? The rule of thumb is you can cover controversy but don’t engage in it. Wikipedians therefore present the facts as they exist.
Automated programmes (bots) patrol Wikipedia and can revert unhelpful edits & copyright violations within minutes. The edit history of a page is detailed such that it is very easy to revert a page to its last good state and block IP addresses of users who break the rules.
“What underlies Wikipedia, at its very heart, is this fundamental idea that more people want to good than harm, more people want to create knowledge than destroy, more people want to share than contain. At its core Wikipedia is about human generosity.” – Katherine Maher, Executive Director of the Wikimedia Foundation in December 2016.
This idea that more people want to good than harm has also been borne out by researchers who found that only seven percent of edits could be considered vandalism.

Wikipedia in the Classroom
Developing information literacy, online citizenship and digital research skills.
The residency has met with a great many course leaders across the entire university and the interactions have all been extremely fruitful in terms of understanding what each side needs to ensure a successful assignment and lowering the threshold for engagement.
Translation Studies MSc students have completed the translation of a Wikipedia article of at least 4000 words into a different language Wikipedia last semester and are to repeat the assignment this semester. This time asking students to translate in the reverse direction from last semester so that the knowledge shared is truly a two-way exchange.

The Translation MSc assignment
World Christianity MSc students undertook an 11-week Wikipedia assignment as part of the ‘Selected Themes in the Study of World Christianity’ class. This core course offers candidates the opportunity to study in depth Christian history, thought and practice in and from Africa, Asia and Latin America. The assignment comprised of writing a new article, following a literature review, on a World Christianity term hitherto unrepresented on Wikipedia.
“When you hand in an essay the only people that generally read it are you and your lecturer. And then once they both read it, it kind of disappears and you don’t look at it again. No one really benefits from it. With a Wikipedia assignment, other people contribute to it, you put it out there for everyone to read, you can keep coming back to it, keep adding to it, other people can do as well. It becomes more of a community project that everyone can read and access. I really enjoyed it.” – Nuam Hatzaw, World Christianity MSc student.

The World Christianity MSc assignment.
Reproductive Biology Honours students in September 2015 researched, synthesised and developed a first-rate Wikipedia entry of a previously unpublished reproductive medicine term: neuroangiogenesis. The following September, the next iteration was more ambitious. All thirty-eight students were trained to edit Wikipedia and worked collaboratively in groups to research and produce the finished written articles. The assignment developed the students’ research skills, information literacy, digital literacy, collaborative working, academic writing & referencing.
One particular deadly form of ovarian cancer, High grade serous carcinoma, was unrepresented on Wikipedia and Reproductive Biology student Áine Kavanagh took great care to thoroughly research and write the article to address this; even developing her own openly-licensed diagrams to help illustrate the article. Her scholarship has now been viewed over sixteen thousand times adding an important source of health information to the global Open Knowledge community.
“It was a really good exercise in scientific writing and writing for a lay audience. As a student it’s a really good opportunity. It’s a really motivating thing to be able to do; to relay the knowledge you’ve learnt in lectures and exams, which hasn’t really been relevant outside of lectures and exams, but to see how it’s relevant to the real world and to see how you can contribute.” –Áine Kavanagh.

The Reproductive Biology Hons. assignment.
Following a successful multidisciplinary approach, including students and staff all collaborating in the co-creation & sharing of knowledge, the residency has been extended into a third year until January 2019. Twenty members of staff have also now been trained to provide Wikipedia training and advice to colleagues to help with the sustainability of the partnership in tandem with support from Wikimedia UK.
While also ensuring Wikipedia editing is both embedded in regular digital skills workshops, demystifying how to begin editing Wikipedia has been a core focus of the residency, utilising Wikipedia’s new easy-to-use Visual Editor interface. Over two hundred videos and video tutorials, lesson plans, case studies, booklets and handouts have been created & curated in order to lower the threshold for staff and students to be able to engage with the Wikimedia projects in the years ahead.

The way ahead
Ten years after Wikipedia first launched, the Chronicle of Higher Education published an article by the vice president of Oxford University of Press acclaiming that ‘Wikipedia had come of age’ and that it was time Wikipedia played a vital role in formal education settings. Since that article, the advent of ‘Fake News’ has engendered discussions around how best to equip students with a critical information literacy. For Wikipedia editors this is nothing new as they have been combatting fake news for years and source evaluation is one of the Wikipedian’s core skills.

In fact, there is increasing synchronicity in that the skills and experiences that universities and PISA are articulating they want to see students endowed with are ones that Wikipedia assignments help develop. The assignments we have run this year have all demonstrated this and are to be repeated as a result. The case for Wikipedia playing a vital role in formal education settings has never been stronger.
Is now the time for Wikipedia to come of age?
If not now, then when?

Course leaders at Edinburgh University
Postscript: All three assignments from 2016/2017 are continuing in 2017/2018 because of the positive feedback from staff and students alike.
These are being augmented with collaborations with:
- two student societies; the History Society for Black History Month and the Translation Society on a Wikipedia project to give their student members much-needed published translation practice.
- Library and University Collections to add source metadata from 27,000 records in the Edinburgh Research Archive to Wikidata and 20+ digitised theses to Wikisource
- a further three in-curriculum collaborations in Digital Sociology MSc, Global Health and Anthropology MSc and Data Science for Design MSc.
- the Fruitmarket Gallery and the university’s Centre for Design Informatics for a Scottish Contemporary Artists editathon.
- A Litlong editathon as part of the AHRC ‘Being Human’ festival.
- The School of Chemistry for Ada Lovelace Day to celebrate women in STEM.
- the University Chaplaincy to mark the International Storytelling Festival.
- Teeside University to run a ‘Regeneration’ themed editathon.
As we have shown, there are huge areas of convergence between the Wikimedia projects and higher education. The Edinburgh residency has demonstrated that collaborations between universities and Wikimedia are mutually beneficial and that Wikipedia plays a vitally important role in the development of information literacy, digital research skills and the dissemination of academic knowledge for the common good.
That all begins with engaging in the conversation. Building an informed understanding of the Wikimedia projects and the huge opportunities that working together create.

Planting the seed and watching it grow.
Reasons to engage in the conversation


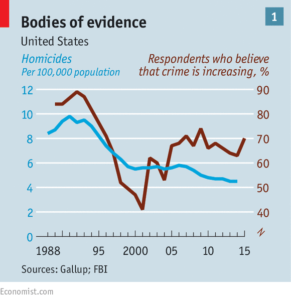 Figure 1 Bodies of Evidence (The Economist, 2016)
Figure 1 Bodies of Evidence (The Economist, 2016)





 A bit of light reading on information retrieval – Own work, CC-BY-SA.
A bit of light reading on information retrieval – Own work, CC-BY-SA.






